L’intelligence artificielle en fiscalité, entre mythe et réalité
Par Rémi Slama – auxiliaire de recherche au Laboratoire de cyberjustice
Si ces dernières années, les technologies dites de l’intelligence artificielle (« IA ») ou le (« machine learning ») ont exercé une influence grandissante sur de nombreuses professions et industries, le monde du droit n’a pas été épargné par ce que certains ont pu désigner comme la 4e révolution industrielle.

Ainsi, de nouveaux outils allant de la recherche juridique améliorée à des systèmes d’analyse plus approfondis en passant par les systèmes d’aide à la décision ont commencé à affecter divers aspects du travail des professionnels du droit.
Pour certains auteurs, les développements récents en matière d’IA dans le traitement du langage naturel et du “machine learning” ont pu défier l’expertise humaine en ce que certaines machines sont capables d’effectuer des tâches de plus en plus complexes, aussi bien, voire mieux que leurs concepteurs humains.
–
Genèse d’une IA appliquée à la fiscalité

En matière fiscale, on peut situer la genèse de l’IA aux années 1970 lorsque L. Thorne McCarty (également considéré comme « le père de l’intelligence artificielle et du droit ») a développé le « Taxman », un système conçu à l’origine comme une forme très préliminaire de raisonnement juridique limité au droit fiscal américain (en fiscalité des réorganisations de sociétés). Le système Taxman était notamment censé déterminer si une réorganisation de sociétés devait ou non être exonérée d’impôts sur le revenu à la lumière de la loi fiscale américaine.
Il est intéressant de noter que le professeur L. Thorne McCarty estimait lui-même dès le départ que l’un des domaines les plus appropriés pour explorer les possibilités de l’IA était le droit fiscal des entreprises. En effet, les problématiques juridiques et fiscales liées à la vie des entreprises sont particulièrement « techniques » et complexes à appréhender pour les avocats.
Ces « abstractions commerciales » en ce qu’elles sont des « systèmes artificiels et formels vidés d’une grande partie du contenu du monde ordinaire », seraient particulièrement bien adaptées pour être appréhendées par l’IA.
A contrario, les matières juridiques empreintes de l’expérience humaine ordinaire comme le droit civil ou le droit pénal seraient plus difficiles à appréhender par l’IA dans la mesure où elles nécessitent une compréhension et une expérience humaine inhérente au juriste, mais particulièrement étrangère à l’IA.
Pourtant, les premiers projets d’IA en matières juridique et fiscale ont été critiqués parce qu’ils n’étaient pas capables de faire preuve d’un raisonnement juridique réel, lequel nécessite « l’interprétation de documents textuels » comportant un langage naturel que les programmes informatiques comprennent difficilement.
En d’autres termes, la concordance entre les concepts juridiques et les caractéristiques d’un cas de pertinence relative à ces concepts n’était pas automatique et nécessitait un raisonnement juridique que la machine n’était pas capable de produire.
C’est parce que le raisonnement juridique peut être particulièrement complexe que la poursuite des innovations en la matière s’est essentiellement concentrée sur des projets utilisant l’IA pour des tâches bien définies dans un domaine du droit précis et concernant une juridiction bien déterminée.
L’IA comme une réponse possible à la complexification récente de la fiscalité
Au début des années 2000, il était assez clair que les technologies utilisant l’IA seraient développées non pas pour remplacer les professionnels du droit, mais pour leur permettre d’exécuter leurs tâches à un niveau plus élevé.
Il est vrai que la matière fiscale s’est largement complexifiée ces dernières années, principalement parce que les départements fiscaux d’entreprises et les prestataires de services en fiscalité (qu’ils soient avocats ou consultants) ont dû composer avec un environnement législatif et règlementaire très changeant, voire instable, que cela soit en fiscalité nationale comme internationale.
L’exigence de transparence et la lutte contre l’évasion fiscale, voire de l’évitement fiscal des multinationales et des grandes fortunes sont devenues de plus en plus prégnantes pour les opinions publiques depuis une quinzaine d’années.
Il faut dire qu’avec la crise économique de 2008 dite des « sub-primes », les politiques d’austérité qui s’en sont suivies, le LuxLeaks, OpenLux, Offshore Leaks (avec notamment les Pandora Papers, les Panama Papers et les Paradise Papers), ou encore SwissLeaks, l’obsession de la transparence insufflée par quelques consortiums de journalistes ne s’est pas tarie.
S’il ne fallait citer qu’un changement majeur à destination des multinationales, le programme BEPS (Base Erosion and Profit Shifting) initié par l’OCDE avait pour but affiché de doter les gouvernements « d’instruments nationaux et internationaux pour lutter contre l’évasion fiscale en s’assurant que les profits soient taxés à l’endroit même où ceux-ci sont générés et où a lieu la création de valeur ».

Au départ en 2012, si cette initiative avait pu faire sourire, la conclusion par de nombreux pays de conventions multilatérales « destinées à mettre rapidement en œuvre une série de mesures relatives aux conventions fiscales pour actualiser les règles fiscales internationales et réduire les possibilités d’évasion fiscale par les entreprises multinationales » a particulièrement modifié les règles fiscales internationales et nationales et a entraîné un bouleversement de la planification fiscale des entreprises.
Cette instabilité, combinée avec une surveillance accrue des autorités fiscales et une exigence de transparence de plus en plus sévère a pu constituer un défi pour les entreprises. Ce défi n’est pas seulement l’exigence de conformité aux lois fiscales ; il faut également s’assurer de l’exactitude, de la cohérence et de la conservation sécuritaire des données fiscales.
La responsabilité des professionnels de la fiscalité implique qu’ils doivent quant à eux fournir des conseils fiables et précis à leurs clients pour protéger leur situation fiscale.
Dans le contexte actuel, sans aller même jusqu’à évoquer la fraude, tout oubli ou erreur de leur part pourraient avoir un impact particulièrement négatif sur l’image d’une entreprise et la perception qu’en a le public.
Parallèlement à ces bouleversements, les administrations fiscales elles-mêmes se sont dotées de technologies innovantes utilisant l’IA et le « machine learning » ou encore le « data mining » afin d’améliorer l’efficacité dans la lutte contre la fraude fiscale et une meilleure collection des taxes.
À ce titre, l’administration fiscale américaine, pour ne citer qu’elle, n’hésite pas à consulter les réseaux sociaux des contribuables en utilisant notamment des programmes capables d’analyser leurs données publiques et d’identifier un contribuable susceptible de frauder.
Un procédé similaire est utilisé par l’Agence du revenu du Canada.
Nous n’avons pas pu avoir accès pour des raisons évidentes de confidentialité aux systèmes développés ou utilisés par les administrations fiscales. Mais ce que nous savons, c’est que leur « mue numérique » a bel et bien commencé et que l’utilisation des technologies basées sur l’IA par ces administrations publiques ne fait plus aucun doute.
La complexification des règlementations fiscales, les nouvelles exigences de transparence, la modernisation des administrations fiscales permettant une efficacité accrue dans les contrôles des contribuables et la compétition entre les différents acteurs du conseil fiscal sont un terreau fertile à l’émergence de nombreux systèmes affirmant utiliser l’IA dans le domaine de la fiscalité.
Banc d’essai des principaux systèmes affirmant utiliser l’IA en fiscalité

Ces dernières années, de nouveaux logiciels ont été mis sur le marché à destination des entreprises, des particuliers et bien sûr des conseils fiscaux.
Ils invitent les fiscalistes à céder aux chants des sirènes en leur promettant notamment de rationaliser efficacement les flux de travail, de fournir des informations précieuses, de réduire les tâches chronophages ou encore d’augmenter la productivité.
Parce que beaucoup affirmaient utiliser l’IA suivant l’approche connexionniste (« machine learning »), nous avons souhaité réaliser un banc d’essai des logiciels commercialisés les plus répandus sur le marché à l’heure actuelle.
Dans un premier temps, nous avons pu essayer Turbotax , un système bien connu sur le marché nord-américain. Il a été développé par la société Intuit pour aider les contribuables à réaliser leur déclaration fiscale.
En pratique, l’utilisateur doit répondre sur une plateforme dédiée à un certain nombre de questions sur sa situation fiscale. Les données issues de ses réponses sont ensuite analysées par un algorithme préalablement à l’émission d’une déclaration fiscale.
Pour des problématiques plus complexes, une assistance est proposée au contribuable sous la forme d’une mise en relation en ligne avec des conseillers fiscaux ou des comptables.
D’après ses concepteurs, le « matching » entre l’utilisateur et le conseiller fiscal adéquat est permis grâce au « machine learning ».
Pour mettre au point ses logiciels, la société investit également dans différents domaines d’IA autres que le « machine learning ».
Ainsi, Intuit développe l’ingénierie des connaissances pour « codifier les règles de conformité fiscale » et le traitement du langage naturel à partir d’une IA capable d’écouter les paroles prononcées par les contribuables et même de lire des mots écrits, comme le sont les informations figurant sur un document fiscal.
Nous pensons que dans sa version actuelle gratuite, cette solution est efficace pour les déclarations fiscales les plus standards.
Dans ses versions payantes, Turbotax propose au contribuable de faire vérifier sa déclaration fiscale par un professionnel avant d’être validée. Cette option est notamment utilisée lorsque les questions deviennent plus complexes. Un traitement automatique et sans l’intervention d’un professionnel réel reste pour le moment impossible pour ce type de questions.
Cette automatisation n’est probablement qu’une question de temps et les comptables devraient peut-être commencer à s’inquiéter de la pérennité de leur activité.
Nous avons pu également tester Checkpoint Edge et Taxnet Pro, deux systèmes développés par Thomson Reuters.
Si eux aussi prétendent utiliser l’IA et le « machine learning » pour obtenir des résultats de recherche ciblés en moins de temps, nous pensons qu’ils ne constituent ni plus ni moins que des plateformes de recherche évoluées, lesquelles s’inscrivent dans la lignée des systèmes développés dans le courant des années 2000 pour les professionnels du droit (LexisNexis par exemple).
Ces systèmes permettent en effet aux professionnels d’optimiser l’efficacité de leurs recherches dans des bases de données mais ne constituent pas des outils de prédiction permettant de les aider dans leurs décisions.
Nous n’avons pas réalisé l’essai des systèmes développés par Wolter Kluwers qui propose des solutions destinées aux professionnels pour préparer plus facilement des déclarations de revenu, sans pour autant prétendre utiliser l’IA.
Pour trouver un système encore plus avancé utilisant l’IA et capable de prévoir une solution en matière fiscale à partir d’un scénario prédéterminé, il nous a fallu nous tourner vers la start-up Blue J Legal (« Blue J ») fondée par trois professeurs de l’Université de Toronto, Benjamin Alarie, Anthony Niblett, et Albert H. Yoon.
Focus sur le système de prédiction développé par Blue J
La promesse de Blue J est d’utiliser le « machine learning » pour prédire comment les tribunaux trancheraient une problématique fiscale.
L’idée est de faire gagner un temps précieux aux fiscalistes en leur permettant de répondre à cette problématique avec plus d’exactitude et de certitude.
Selon Blue J, le système développé aurait 4 avantages dans la recherche et l’analyse fiscales :
Il serait en effet possible de « quantifier les risques pour les clients, d’identifier les meilleures stratégies de planification fiscale et commerciale, de découvrir les angles morts et d’identifier les stratégies de litige les plus efficaces ».
Blue J garantit une fiabilité des résultats du système de plus de 90%.
Mais comment cela est-il possible ?

Selon ses concepteurs, Blue J utilise une technologie d’apprentissage automatique pour générer un algorithme prédictif, lequel identifiera les connexions parmi différentes variables.
La technologie de l’apprentissage automatique est utilisée pour créer des classificateurs de droit fiscal, lesquels sont basés sur les publications de décisions de justice émanant des juridictions canadiennes (notamment la Cour Suprême du Canada et la Cour d’Appel Fédérale).
Ces décisions sont généralement la confirmation ou l’infirmation d’une question juridique particulière.
Le système est structuré pour répondre avec une certaine probabilité à la manière dont un tribunal déciderait de répondre à ces questions sur la base d’un ensemble de faits donnés.
Dans une première étape, une question de droit axée sur les faits est identifiée. Cette question génère un ensemble de décisions de justice qui y sont reliées ainsi que les facteurs les plus pertinents pour le tribunal au moment de trancher la question.
Lorsqu’un tribunal doit par exemple trancher sur une problématique de conflit de résidence fiscale d’une personne physique, il doit tenir compte d’un certain nombre de facteurs qui tiennent notamment (la liste de ces facteurs n’est ici pas exhaustive) à la nationalité de la personne physique, à la durée de sa présence sur tel ou tel territoire, à ses attaches sur un territoire donné, ou encore au centre de ses intérêts vitaux.
Il est important de noter que lors de cette première étape, la détermination des questions pertinentes représente un processus itératif qui peut prendre un temps important.
L’étape suivante consiste à coder chaque décision publiée conformément aux facteurs susmentionnés.
Ce processus transforme des données non structurées (le texte des avis judiciaires) en données structurées (informations issues des questions précitées sous forme de données variables).
Blue J couvre un pan important des problématiques fiscales (fiscalité des entreprises canadiennes, américaines, fiscalité des personnes physiques, fiscalité internationale pour ne citer qu’elles).
Nous avons pu tester le système pendant plus d’une semaine en matière de fiscalité des entreprises canadiennes, fiscalité des particuliers, et fiscalité internationale sur la base de différents scénarios.
Il nous a notamment été possible de réaliser une simulation portant sur la résidence fiscale d’une personne physique disposant d’une présence importante au Canada et dans un pays tiers.
Pour obtenir une réponse quant à la question de la résidence fiscale de cet individu, il était nécessaire de répondre au préalable à un questionnaire détaillé relatif à la situation de la personne physique (voir un extrait des questions posées dans le tableau de gauche de la capture ci-dessous).
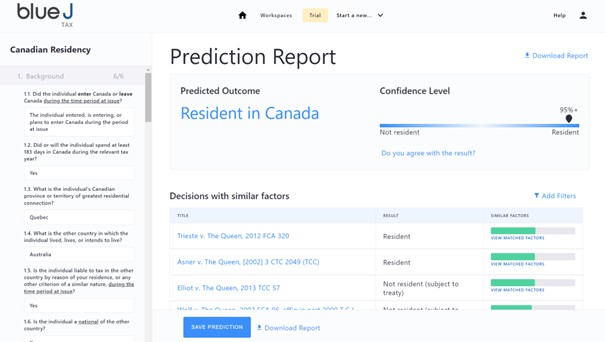
En seulement quelques secondes, le système a émis un rapport contenant les éléments suivants :
-Le résultat probable de la résidence fiscale de l’individu qui en l’occurrence s’est avérée être le Canada ;
-Le pourcentage de probabilité du résultat qui nous a été indiqué comme un résultat certain à 95% ;
-Un mémorandum détaillé expliquant la justification du résultat sur la base des réponses aux questions posées ;
-Un résumé des décisions de justice clés utilisées par le système ;
-Enfin, une liste des décisions de justice les plus similaires à notre cas en fonction de nos réponses aux questions.
Sans cette technologie, il faut reconnaître qu’une analyse « à l’ancienne » d’autant de décisions de justice pourrait prendre des heures à une équipe d’avocats (lesquelles seront facturées au client final).
Outre l’efficience, il est très peu probable que la fiabilité d’une telle recherche soit similaire à celle permise par l’IA.
Blue J permet de générer un mémorandum ou un rapport en utilisant les chartes graphiques du cabinet d’avocat ou du conseiller fiscal si désiré.
Autrement dit, la recherche fiscale (qui peut d’ailleurs mentionner le pourcentage de fiabilité) peut être directement envoyée au client final avec une intervention minime du prestataire de service.
De nos observations précédentes, faut-il en conclure que Blue J a remplacé les avocats fiscalistes ?
Certainement pas, mais il ne fait nul doute que ce système offre une valeur ajoutée importante aux professionnels de la fiscalité.
D’après les dires de Blue J, il serait d’ailleurs utilisé par la majorité des grands cabinets d’avocats d’Amérique du Nord.
Enfin, à la suite des différents entretiens que nous avons eus avec les équipes des sociétés mentionnées plus avant, nous avons compris que la croissance du développement des outils fiscaux utilisant l’IA allait continuer à s’intensifier dans les prochaines années, aussi bien dans le secteur privé, que dans le secteur public.
En matière fiscale comme dans d’autres domaines, il est pour le moment difficile de donner un blanc-seing à l’IA
Le développement des systèmes utilisant l’IA n’est cependant pas sans poser un certain nombre de questions pointées par la doctrine et compilées dans une récente étude universitaire.
Sans en dresser un inventaire exhaustif, il nous a semblé important de mentionner une problématique fondamentale en IA qui est celle des données.
L’apprentissage automatique a besoin d’une quantité importante de données pour être efficace.
Or, cette matière première que sont les données ne peut pas être utilisée librement par les entreprises en raison du fait que les données fiscales des contribuables constituent des renseignements personnels protégés par des lois dédiées, aussi bien au Canada (dans les provinces et au niveau fédéral), que dans d’autres juridictions.

Pour le moment, il n’est d’ailleurs « pas clairement établi » que les développeurs de systèmes fiscaux innovants aient le droit d’utiliser les données fiscales de leurs clients.
À ce titre, pour développer le système de Blue J, ses concepteurs ont utilisé comme source principale, des données issues de la jurisprudence qui étaient par conséquent non protégées et librement accessibles au public.
Une autre problématique majeure inhérente aux données fiscales est celle du respect de la vie privée.
Si l’on se place dans la perspective du secteur public par exemple, il est admis que les administrations fiscales doivent être en mesure de vérifier l’exactitude des informations déclarées par les contribuables.
Mais il apparaît (particulièrement aux États-Unis) que l’administration fiscale est en mesure de récolter notamment sur les réseaux sociaux des quantités de données très importantes lorsqu’elle enquête sur une fraude fiscale potentielle.
Grâce à l’IA, le fisc américain peut avoir un accès facilité aux données issues des réseaux sociaux pour déterminer si un contribuable américain remplit ses obligations fiscales.
Ces données, lorsqu’elles sont combinées avec des informations à caractère privé issues des déclarations fiscales de ces contribuables, peuvent atteindre de manière disproportionnée à leur vie privée.
Certains auteurs pointent même un risque de « Big Brother » impliquant une surveillance par le gouvernement potentiellement « très dangereuse » pour les libertés publiques des citoyens.
Par ailleurs dans un autre registre, la question de la responsabilité civile des agents autonomes, si elle n’est certes pas nouvelle, doit être encore tranchée en droit québécois.
D’un point de vue très concret, l’utilisateur d’un système utilisant l’IA est en droit de se poser cette question :
En effet, si le système de prédiction de Blue J affirme être fiable à 90%, qui serait alors responsable en cas d’erreur causant un dommage in fine au client ?
Le professionnel utilisant le système ? Le développeur du système ou encore son opérateur ?
Nous ne sommes pas sans ignorer que la technologie de l’IA comporte des biais induits par les algorithmes.
Certes, le risque de discrimination induit par ce que l’on appelle le biais algorithmique n’est pas non plus un sujet nouveau ni même propre au domaine de la fiscalité, mais il devrait toujours être considéré lors de l’utilisation d’un système fondé sur l’IA.
Cette utilisation devrait reposer sur un principe de prudence « en anticipant autant que possible les conséquences néfastes de l’utilisation [de l’IA] et en prenant des mesures appropriées pour les éviter ».
Conclusion : dépasser le paradigme de la machine dotée d’IA qui remplacerait l’homme
D’après une étude réalisée sur plus de 700 emplois par les professeurs Carl Benedikt Frey et Michael A. Osborne, le risque de remplacement de l’homme par la technologie dans les prochaines années est très inégal d’un secteur d’activité à l’autre.

Ainsi, les auteurs de cette étude font apparaître que les avocats sont peu susceptibles d’être remplacés par des ordinateurs ou des algorithmes (avec un taux de probabilité de 3.5%).
Mais tout le monde n’est pas logé à la même enseigne.
En effet, la probabilité que les comptables et les auditeurs soient remplacés est bien plus alarmante car l’étude estime qu’elle s’élève à 94% !
Les grands acteurs du conseil fiscal et de l’audit (les Big four notamment pour ne pas les nommer) ont certes déjà diversifié leur portefeuille d’activités depuis un certain temps (avec notamment le conseil en stratégie, la fiscalité, les services juridiques lorsque cela est permis dans leur juridiction d’exercice, ou encore les incubateurs de start-up).
Cependant, il faut reconnaître que le cœur de métier de ces structures est très lié aux activités d’audit et de comptabilité, ce qui nécessite un grand nombre d’auditeurs spécialisés qui facturent des heures de prestations à leurs entreprises clientes dont le coût peut être important.
Ces acteurs l’ont bien compris. Aussi, plutôt que de subir une révolution technologique qui rendrait obsolète leurs activités historiques, la survie du modèle des BIG four dépend de leur capacité à développer des outils plus intelligents pour rester compétitifs dans tous les secteurs dans lesquelles ils officient.
Il n’est donc pas surprenant que Blue J et le bureau de KPMG au Royaume-Uni aient signé très récemment un partenariat portant sur le lancement d’un outil fiscal dédié à cette juridiction.
Parce que les cabinets d’avocats évoluent dans un secteur particulièrement concurrentiel, l’arrivée de systèmes innovants fondés sur l’IA (en fiscalité comme dans les autres disciplines) est susceptible de redéfinir la manière dont les avocats travaillent et interagissent avec leurs clients.
Dans la matière qui nous intéresse ici, ces systèmes peuvent amener une plus grande rapidité, plus de certitude et plus d’efficience aux tâches les plus ingrates et complexes du droit fiscal.
Si certaines structures d’avocats sont encore réfractaires à ce type de technologie, c’est parce qu’elles voient d’un œil inquiet le possible remplacement de certaines tâches s’appuyant historiquement sur le jugement humain, comme la capacité de prévoir ou d’anticiper le résultat d’une décision de justice.
D’autres voient ce virage technologique comme une opportunité prometteuse.
L’IA permettrait notamment une meilleure transparence juridique, un règlement plus sûr et plus efficace des litiges, ou encore une plus grande efficacité dans le travail des avocats.
Sans débattre de la question de la productivité, un essai de la technologie de Blue J a pu nous montrer que l’aide apportée par la machine, en dégageant l’avocat des travaux de recherche les plus fastidieux, est de nature à apporter une certaine sérénité et permet une meilleure concentration de la matière grise du professionnel sur l’approfondissement de la question qui lui est posée.
Par ailleurs, le temps gagné est de nature à permettre au professionnel d’élargir son domaine de compétences et de se concentrer sur d’autres tâches à plus forte valeur ajoutée.
En somme, nous pensons que les outils dotés d’IA en fiscalité comme dans d’autres domaines du droit devraient s’intégrer en bonne intelligence avec les équipes d’avocats.
Il ne faudrait donc pas craindre un remplacement de l’avocat fiscaliste ou du conseil fiscal par la machine, mais plutôt considérer qu’il disposera de nouveaux « outils d’intelligence augmentée, qui aident à [sa] décision », ce qui améliorera in fine la qualité des prestations fournies au client.
Ce contenu a été mis à jour le 21 février 2023 à 11 h 36 min.