Regard sur le Deep Learning
De la reconnaissance faciale à la conduite autonome, en passant par les systèmes d’assistance intelligents (chatbots) et la création artificielle, la puissance des ordinateurs actuels conjuguée à la masse de données désormais disponibles (big data) a rendu opérationnelles plusieurs avancées en matière d’intelligence artificielle. De l’algorithme simplement exécutoire (p.ex. calculatrice) à une intelligence artificielle capable d’effectuer des tâches d’une complexité croissante, la percée technologique est redevable au perfectionnement de l’apprentissage automatique (machine learning) – dont l’apprentissage profond constitue une approche particulièrement prometteuse. En quoi consiste-elle ?
L’expression machine learning vient d’Arthur Samuel (1901-1990)i, pionnier américain de l’intelligence artificielle connu pour avoir développé, dès 1952, le tout premier programme d’auto-apprentissage du jeu de dames (Samuel Checkers-playing Program). L’apprentissage automatique cherche à développer chez l’ordinateur la capacité d’apprendre, d’optimiser sa performance sans avoir été explicitement programmé. L’objet de l’apprentissage n’est pas tant l’exécution de tâches/instructions spécifiquement programmées que le développement d’une plus grande adaptabilité opérationnelle de la machine en fonction du contexte, à partir d’un cadre de référence pertinent à l’ordinateur et entretenu par l’algorithme.
L’enjeu consiste à modéliser cette adaptabilité opérationnelle à l’aide de fonctions complexes reliant différentes variables les unes aux autres sur une base probabiliste. Tom M. Mitchell, président du département Machine Learning de l’Université Carnegie Mellon (CMU) à Pittsburgh (Pennsylvanie), décrit en ces termes les principes généraux sous-tendant cet apprentissage « expérientiel » appliqué à l’ordinateur :
« A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E. » (Mitchell, 1997 à la p 2)ii
L’expérience (E) réfère à l’ensemble des données d’entraînement à partir desquelles l’algorithme bâtira et affinera son modèle analytique ou prédictif. Les tâches (T) dont il est question consistent à appliquer ce modèle aux nouvelles constellations de données dont les interrelations n’ont pas été testées. La performance (P) du programme se mesure à la validité appliquée de ce modèle dans ses tâches d’analyse ou de prédiction à partir des données (nouvelles) initiales.
Cet apprentissage automatique par l’expérience peut être principalement supervisé, non supervisé ou par renforcement. Entre un apprentissage supervisé et non supervisé, la distinction réside dans l’étiquetage (ou non) des valeurs de sortie attendues des algorithmes à partir des données d’entraînement. En d’autres mots, un apprentissage automatique est dit supervisé lorsque le programme bénéficie, aux fins d’ajuster sa modélisation et de renforcer sa fonction prédictive, d’une rétroaction continue sur les « bonnes réponses » attendues ou devant être trouvées à partir des données initiales ou valeurs d’entrée. Un apprentissage dit non supervisé, de l’autre côté, laisse à l’algorithme le soin d’en découvrir la distribution statistique des échantillons d’entraînement afin d’en faire ressortir tendance et dispersion. Plus analytique que prédictif, l’apprentissage automatique non supervisé partage ainsi quelques similarités avec le forage de données (data mining) utilisé notamment en matière de détection de fraude sur la base d’anomalies de comportement considérées comme (des données) aberrantes.
De son coté, l’apprentissage par renforcement permet au système intelligent d’agir directement sur son environnement, moyennant un contrôle stratégique des résultats obtenus sous forme de récompense ou de punition. À la différence de l’apprentissage supervisé, la bonne démarche n’est plus suggérée au système, lequel doit la trouver par lui-même par essais et erreurs. À cet égard, un contrôle minimal est exercé sur les résultats de ces essais sous forme de récompense (bonne réponse) ou de punition (mauvaise réponse), l’objectif assigné au système étant de maximiser le cumul de ses récompenses. En élaborant leur propre stratégie optimale plutôt qu’en se fiant uniquement à l’expertise ou à l’expérience humaine, des algorithmes apprenant par renforcement ont surpassé la performance des meilleurs acteurs humains notamment dans les jeux de Go (Silver et al, 2017)iii ou Atari (Mnih et al, 2017)iv.
En pratique, les différentes méthodes d’apprentissage sont souvent utilisées de façon combinée pour en optimiser les résultats, et plusieurs situations peuvent en nécessiter l’hybridation.
L’apprentissage profond (ou deep learning) est une sous-catégorie de méthodes d’apprentissage automatique. Il peut être appliqué de façon supervisée, non supervisée ou par renforcement. Sous forme d’un réseau de neurones artificiels calqués sur le fonctionnement de notre système nerveux, l’apprentissage profond cherche à optimiser la modélisation de relations complexes entre variables à l’aide d’une organisation en couches de neurones interconnectées. La profondeur du réseau, caractérisée par le nombre de couches neuronales intermédiaires, permet de favoriser une convergence progressive et optimisée vers la valeur finale. Cette dernière s’obtient au terme de nombreux calculs effectués par des neurones artificiels qui sont autant de fonctions (mathématiques) complexes à plusieurs variables. L’interconnexion entre différentes couches neuronales consiste à « recycler » les résultats obtenus des calculs d’une couche neuronale précédente pour les appliquer comme valeurs d’entrée à la couche subséquente, et ainsi de suite, jusqu’à l’obtention de la valeur finale (figure 1).
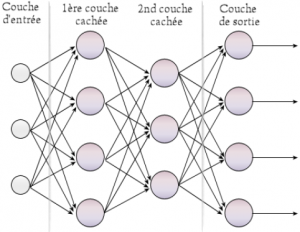
Figure 1 : Réseau de neurones artificiels
Source : http://penseeartificielle.fr/focus-reseau-neurones-artificiels-perceptron-multicouche/
Les résultats sont modulés non seulement par le nombre, les types ou la grandeur numérique des valeurs d’entrée, mais également par leur poids (weight) ou importance relative, mimant la fameuse plasticité synaptique essentielle dans la mémorisation et l’apprentissage de notre système nerveux. C’est également cette pondération ou importance relative accordée aux différentes valeurs ou variables d’entrée qui se trouve ajustée au cours d’un apprentissage supervisé, à l’aide d’un algorithme dit de rétropropagation (backpropagation) du gradient. Cet algorithme évalue l’écart entre la valeur finale attendue et la valeur de sortie calculée (ce qu’on appelle le gradient de l’erreur). Pour minimiser ce gradient, l’algorithme se doit de remonter vers l’arrière au travers des couches intermédiaires jusqu’à redéfinir les poids synaptiques de départ. Dans cette perspective, apprendre revient donc à déterminer les coefficients synaptiques les plus adaptés à classifier les exemples présentés.
Qu’il s’agisse d’un apprentissage automatique supervisé ou non, l’un des défis s’avère le caractère généralisable des résultats acquis par expérience. Les promesses de l’apprentissage automatique reposent sur la capacité du programme à exécuter les tâches attendues à partir de données nouvelles (non apprises) avec autant de justesse, en étendant ainsi les résultats de son observation expérientielle à un nombre suffisamment élevé de nouveaux cas. À cet effet, non seulement la disponibilité des (jeux de) données initiales s’avère indispensables, mais encore les données d’entraînement doivent constituer un échantillon représentatif des probabilités d’occurrence des divers événements, de sorte que la machine puisse construire un modèle prédictif suffisamment performant pour être applicable à un grand nombre de situations nouvelles. Pour sa part, l’apprentissage par renforcement s’avère prometteur notamment en robotique et navigation autonome, pour permettre aux systèmes d’interagir avec leur environnement; toutefois, il peut pécher par une très grande variance et un aiguillage délicat des différents essais.
Jie Zhu
i Arthur Samuel, « Some Studies in Machine Learning Using the Game of Checkers » (1959) 3 IBM Journal 211.
ii Tom M. Mitchell, Machine Learning, McGraw Hill, 1997 à la p 2, en ligne: https://www.cs.ubbcluj.ro/~gabis/ml/ml-books/McGrawHill%20-%20Machine%20Learning%20-Tom%20Mitchell.pdf
iii David Silver et al, « Mastering the game of Go without human knowledge » (2017) 550 Nature 354, DOI: 10.1038/nature24270
iv Volodymyr Mnih et al, « Human-level control through deep reinforcement learning » (2015) 518 Nature 529, DOI: 10.1038/nature14236
Blogue réalisé grâce à la Chaire Lexum.
Ce contenu a été mis à jour le 24 juillet 2018 à 13 h 34 min.